From fragmented data estates to a unified, governed Fabric platform — we consolidate ingestion, storage, and analytics into one connected experience.
Fragmented data estate — Data lives across SQL, ADLS, Synapse, third-party warehouses, and SaaS exports — every report needs a pipeline through three different tools.
Stale reports, slow refresh — Overnight ETL jobs miss SLAs and executives open dashboards showing yesterday's reality — not today's.
Spiralling data platform spend — Separate bills for storage, compute, ETL, and BI pile up — there's no single view of cost, capacity, or who's driving consumption.
No safe self-service — Analysts wait weeks for IT to surface new tables — and shadow workspaces multiply because central governance feels too slow.
Real-time data trapped in OT systems — Telemetry, IoT, and event streams never reach the analytics layer fast enough to drive operational decisions.
Lakehouse vs Warehouse confusion — Teams choose the wrong Fabric workload for the use case and end up with duplicated data, awkward joins, and unexpected costs.
Capacity throttling & smoothing — Workloads compete for the same F-SKU capacity, throttling kicks in, and refreshes queue up with no observability into who's consuming what.
Migration from Synapse / Databricks — Lift-and-shift attempts break because Spark pools, pipelines, and security models don't map 1:1 onto Fabric workloads.
Direct Lake fragility — Models fall back to DirectQuery silently when schemas drift, partitions explode, or RLS isn't designed for V-Order semantics.
OneLake governance gaps — Workspaces sprawl, shortcuts duplicate, and lineage breaks because nobody owns the domain / workspace / item taxonomy.
Tell us a little about your situation — we'll suggest the right Microsoft solution for you.
Real Fabric platforms delivered across multiple industries.
Petabyte-scale network event data sat across 7 legacy warehouses with no unified analytics capability.
An end-to-end Power BI solution helping a tourism business decode customer behaviour, refine package strategy, and surface fresh growth opportunities.
Our customer basically needs to extract health care data from their databases into flat files. The data is very bulky. The customer is well versed in SQL and wishes to utilize this fact and develop an SSIS package that eliminates the need of SSIS knowledge for their employees, leverage their knowledge of SQL and make extracts possible by just writing stored procedure(s).
We bring deep Synapse, Spark, and Power BI heritage into Fabric — designed for scale, governed by OneLake, and tuned for capacity from day one.
Our Fabric practice covers domain modelling, workspace topology, medallion design, and capacity planning — turning Fabric from a tool sprawl into a single, governed data platform that serves analytics, AI, and operations. We bring battle-tested patterns from Synapse and Databricks engagements into Fabric-native designs.
From a green-field Lakehouse to a federated multi-domain Fabric estate, we design for cost, performance, and governance simultaneously.
From assessment to production — we cover every Fabric workload end to end.
Current-state analysis, workload mapping, capacity sizing, and target architecture so you adopt Fabric where it pays off — not as a forced lift-and-shift.
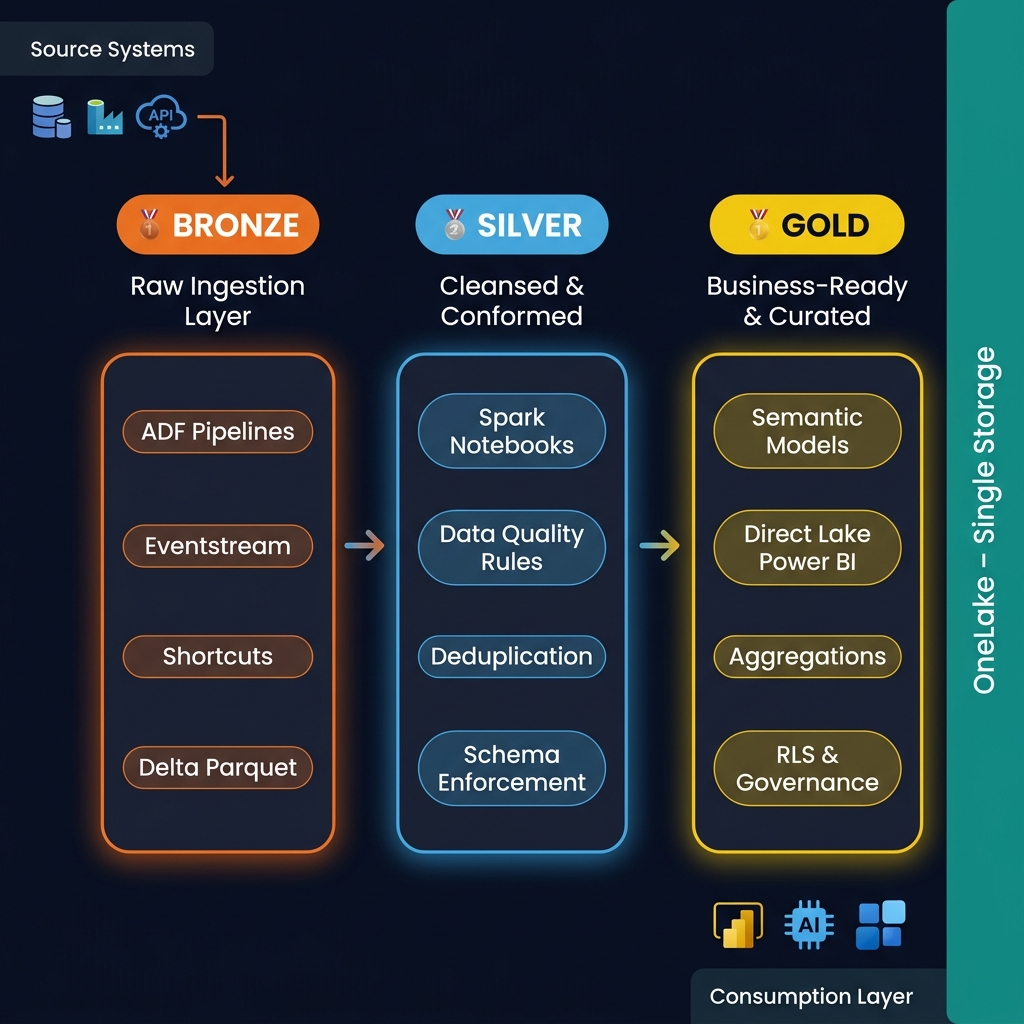
Medallion bronze/silver/gold design in OneLake, delta-parquet optimisation, V-Order, and warehouse modelling for analytics and downstream AI consumption.
Fabric Data Factory ingestion from SaaS, on-prem, and SQL — with dataflows, copy jobs, mirroring, and parameterised pipelines wired into source control.
Eventstreams, KQL databases, and Data Activator triggers powering operational dashboards and event-driven actions on streaming data.
Workload-by-workload migration plans, code conversion, schema mapping, and parallel-run validation to move from Synapse or Databricks onto Fabric safely.
Domain & workspace taxonomy, OneLake security, capacity monitoring, autoscale strategy, and FinOps reporting for sustainable Fabric operations.